As part of my passion project at the Metis Data Science bootcamp, I created a video presentation that explains how a collaborative filtering recommender works and designed an anime recommender based off its structure.
This is the 5th and final project of the Metis Data Science bootcamp. Compared to the previous 4 projects, this one is termed the “Passion Project”. Essentially it’s a project that expresses our passion and reflects what we’ve learned and want to focus on from the bootcamp.
For project 4, we covered recommender systems and I saw many of my fellow cohort members create recommenders for their project 4. I was inspired to create my own but one that wasn’t reliant on NLP.
I also came across the concept of Collaborative Filtering (CF) recommenders while I was brainstorming and became very interested in them. Compared to the recommenders that were created for project 4, all of them were Content-Based (CB) recommenders so I thought it’d be interesting to bring a new type of recommender to the table. In layman’s terms, CF recommenders work by returning predictions that are based off similar users’ reviews and recommendations.
They’re actually quite simple to implement but can become very complex depending on the degree of recommendation. CF recommenders are also quite popular and have become popularized by many big name companies such as Amazon and Netflix.
Many CF recommender project examples online are created by running movie data into the model. Looking back at my past projects, I decided to reference back to project 2, which dealt with data from MyAnimeList (MAL) and thought implementing that data would be very similar and I wanted to try it out.
Also, I feel that it wouldn’t really be a “Passion” project unless it was something I was truly passionate about. To briefly provide some background, I’ve literally grown up with anime. When I was little, my oversea relatives would always send us gifts like studio ghibli movies and doraemon manga. This was pretty much my media back then and it expanded when the library became a weekly trip for me. I would always borrow manga and anime DVDs from the library. Then came the internet. As the internet expanded, so did the accessibility of online media and people would start watching their anime there. The internet was basically my gateway to exploring the genre of anime and because of my interest growing up, I would literally watch anything that I found interesting, i.e. a couple thousand shows starting from high school.
Ironically, because I’m known as someone who’s watched so much anime, I’m always asked for recommendations. Truthfully, that’s not an easy task when I don’t really know what that person likes. Which brings us to this recommender. I may not be able to tell you what to watch but I can guarantee you this recommender probably can. My goal is to create a recommender that both new and existing anime fans can benefit off of and help them explore the world of anime.
Data
The data I used was requested off an API called Jikan. Jikan is a unofficial open source API built for MAL. Compared to other MAL APIs, Jikan is widely supported and offers wrappers for multiple programming languages. Also, at least from what I looked up, Jikan was the only one that offered anime review data, which is a crucial part of creating a CF recommender.
The main information I pulled was requested off the top anime pages, which consisted of 50 shows/movies per page, and stored the anime’s title, the user who made the review, and the user’s review score. I also stored the anime’s MPAA rating and its genres for later usage as I wanted a way to be able to filter through the recommendations.
And to make things easier for myself, I created unique numerical IDs for each anime and user in my data so my model could reference them later.
Methodology
While I was researching CF recommenders, I came across a package called Surprise. Surprise is a python package that’s actually built specifically for CF recommenders and it’s quite easy to implement. Because of that, I chose it to be the backend for my model.
However to optimize Surprise, you need to make sure you have enough reviews and users to compare with one another, otherwise you’ll face a penalty in accuracy. Because I wanted this to work with users who were new to anime and have watched a couple of shows, I set the threshold quite low to include shows and users with at least 2 ratings each. You may think that’s not a good idea but as you continue reading, it wasn’t that bad!
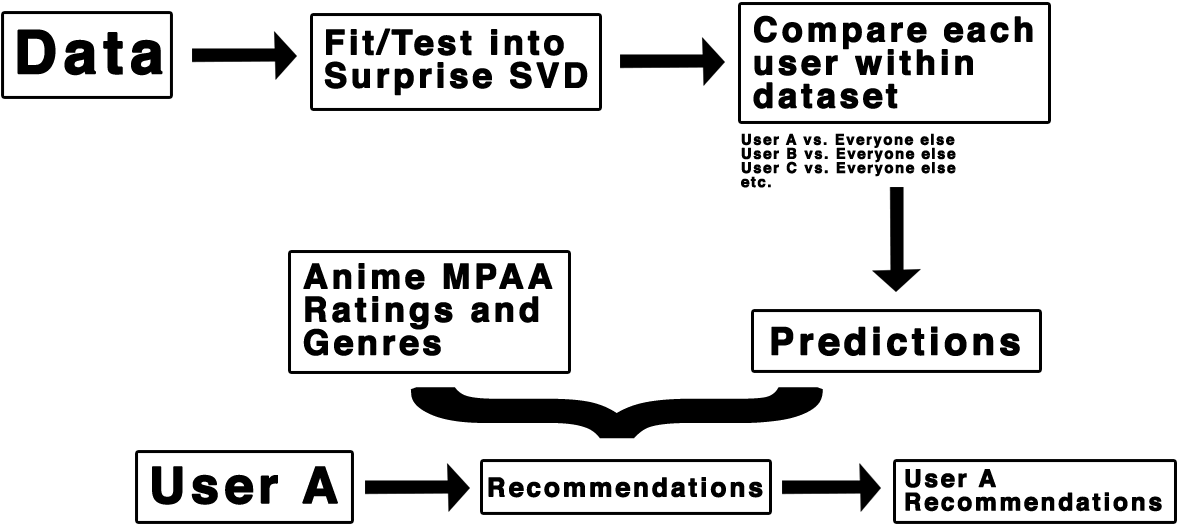
One of the algorithms in the Surprise library is called Singular Value Decomposition (SVD) and is one I chose to base my model off of. SVD is a matrix factorization algorithm and it tries to find the minimum error of the predicted and known rating scores between users. Essentially, the predictions are a comparison of each user’s scores vs. everyone else’s and returns whichever anime comes close to their existing review scores.
After doing a fit and test on my data, I got a RSME of 0.65 on my returned prediction matrix. If you’re not familiar with RSME (Root Mean Squared Error), it represents the difference between the predicted and actual scores. The closer it is to 0 means the more accurate the predictions become. It shows that this is actually a pretty good model!
But we’re not done yet. We’ve got to change the predictions into recommendations. So I took the information from the predictions matrix and create a pandas dataframe from it, which was then merged with the ratings and genres that I pulled earlier in order to filter through the dataframe. In order to come up with a user’s recommendations, we need to pass into our existing recommendations data a user’s existing reviews. What returns is the predictions of that user, not including shows they’d previously reviewed/watched.
Streamlit
As mentioned earlier, I wanted this to be something people can use. So I created an interactive streamlit app and deployed it on Heroku! You can access the app here.
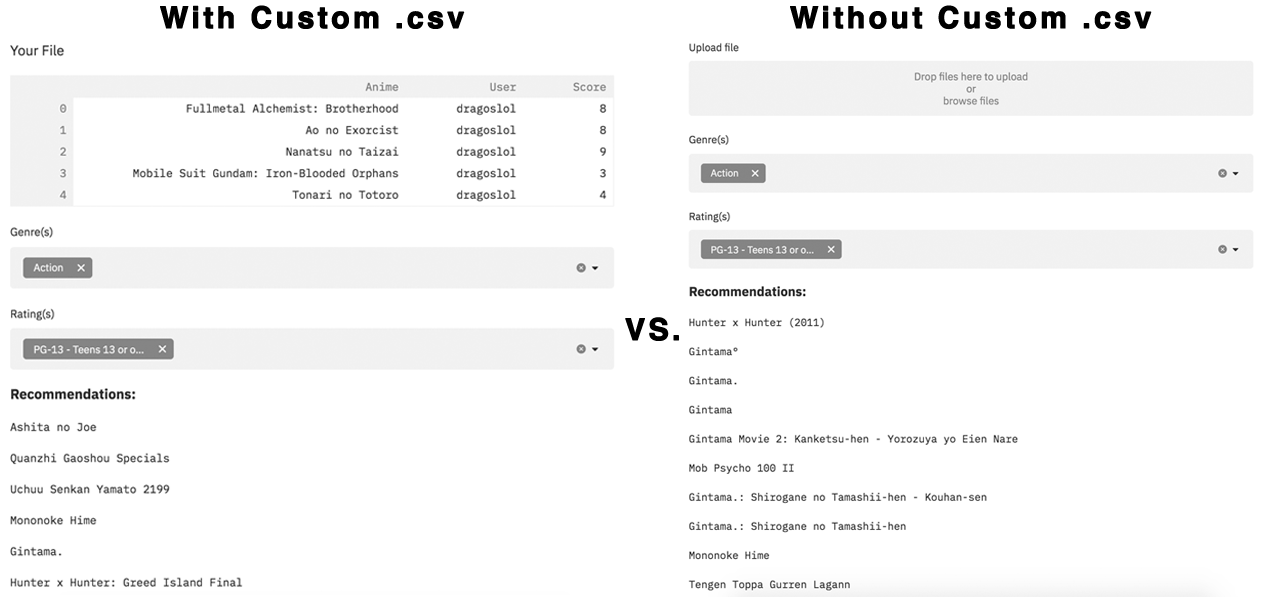
There are 2 main features of this app. The first is a file upload that allows you to upload a .csv of the shows you’ve watched and your own review scores. The uploaded file is then concatenated onto the original data pulled from MyAnimeList, which the model will take and compare you with all other users.
As mentioned earlier, the results returned are based off of users that have reviewed the same shows as you and provides recommendations on shows they’ve scored similarly but are not within your own review history.
Secondly, you can filter out your recommendations by doing a multiselect of genres and ratings included within the returned data. The app then returns the top 10 recommendations based off of your selected features.
I should mention that I kept the file upload optional and the user could very well return data without it. I wanted to be versitile with the usage of this app and allow new and familiar anime fans to enjoy it. The only difference between the returned results is the personal interests of each one.
Conclusion
To conclude, collaborative filtering does a really good job of user-based predictions on a simple level. Though we sometimes mystify the inner workings of these recommenders, they’re actually quite easy to understand and implement.
Lastly, you, the reader, now have your own anime recommender! I hope that this recommender becomes either your gateway to anime or helps you explore the world of anime. Not to mention, it gives you something fun to do during this pandemic!